
May/June 1996
Steve Malone
E-mail: steve@geophys.washington.edu
Geophyics AK-50
University of Washington
Seattle, WA 98195
Phone: (206) 685-3811
Fax: (206) 543-0489
FOREWORD
During the past year the Electronic Seismologist column focused on various aspects of the Internet from a seismologist's perspective. During the coming year this column will cover in some detail several specific sources of seismic data and information. Major data centers will be the topic of two columns, and special data access techniques such as automatic data request managers (AutoDRM) will also be covered. Guest authors for this column are encouraged. If anyone has a short article which might be appropriate for this column please contact Steve Malone (steve@geophys.washington.edu).
In this issue the guest author for the Electronic Seismologist is Dr. Tim Ahern, the Program Manager for the Incorporated Research Institutions for Seismology (IRIS) Data Management System (DMS). Many people's main contact with IRIS is through the IRIS Data Management Center (DMC), the heart of the DMS. Located in Seattle, Washington, the DMC is responsible for archiving and distributing the products of the other major programs of IRIS, the Global Seismic Network (GSN) and the Program for Array Seismic Studies of the Continental Lithosphere (PASSCAL). Other parts of the Data Management System include data collection centers, data quality-control groups, and analysis and development groups. Details of the IRIS organization and activities can be electronically accessed through the WWW at http://www.iris.edu.
For many newcomers to the IRIS DMC, sorting through the wealth of information and data stored there can be initially confusing. The following article gives a nice overview of how the IRIS DMC has developed, the nature of the data stored there, and, most importantly, a comprehensive summary of many of the tools to assist the user in finding and obtaining the data or information of interest. While the Electronic Seismologist appreciates the easy-to-remember agrarian-based names of many of the data access programs and facilities of the DMC, he does not necessarily approve of the specific acronyms they are supposedly based on. However, if the exponential trend for data volume shown in some of the following figures is an accurate forecast of the future, then such access tools, by any name, will be increasingly important to assist us in getting to the data we need. One important service of the IRIS DMC not covered in this current article is the near-real-time waveform acquisition system called SPYDER. Since the Electronic Seismologist was the original developer of the SPYDER system, he will cover it in detail in a later column.
THE IRIS DATA MANAGEMENT CENTER
Tim Ahern
IRIS DMS Program Manager
1408 NE 45th Street #201
Seattle, WA 98105
tim@iris.washington.edu
The IRIS DMC's principal task is to archive data from the IRIS GSN and PASSCAL programs and to distribute these data to researchers when requested. Nevertheless, the IRIS DMC also acts as a central archive and distribution point for data from a variety of other networks. One of the most important data sets is from the Federation of Digital Seismographic Networks (FDSN). In its role as the FDSN Data Center for Continuous Data, the IRIS DMC routinely receives data from most members of the FDSN including Canada, China, Czech Republic, France, Germany, Italy, Japan, and Russia, as well as data from several arrays and networks operated by IRIS in the former Soviet Union. Some historical data from the Iranian Long Period Array (ILPA), the Alaskan Long Period Array (ALPA), and the Large Aperture Seismic Array (LASA) are also archived. The DMC acts as the archive and distribution point for data from the Southern California TERRAscope network as well as the primarily short-period data from the Pacific Northwest Seismic Network. IRIS is now a member of the Council of the National Seismic System (CNSS), which coordinates activities of most regional networks within the United States as well as the U.S. National Seismic Network. Plans are now in place to archive selected data from the Northern California Network, the ANZA array, and it is likely that data from most other members of the CNSS will be made available either through the IRIS DMC or the Northern California Earthquake Data Center (NCEDC) at UC Berkeley.
The IRIS DMC implemented a new method of parallel archiving during the past year, which allowed us to increase significantly the rate at which data can be archived as well as increase the number of independent data sources that can be archived simultaneously. Figure 1 shows the amount of data from permanent seismic recording stations now in the IRIS DMC archive. This graph does not include data from temporary deployments such as PASSCAL. Most of the data in the archive have been compressed to where one byte generally contains one sample. Data are stored in two different sorted orders in the archive, once by time and once by station.
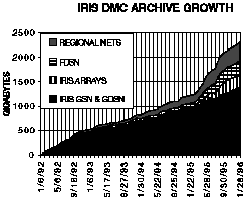
Figure 1. This figure shows the growth in the IRIS DMC since it moved to Seattle in 1992. Although data from more than two dozen networks are archived at the DMC, this diagram groups them into four fundamental types of seismic sources for clarity of presentation. Prior to 1995, the rate of growth of the archive was roughly 330 gigabytes per year. During 1995 it increased to about 1500 gigabytes (1.5 terabytes) per year.
Two features are very noticeable in Figure 1. Although the figure groups data into the four primary types of data sources, the number of networks archived actually increased from four to twenty-four during 1995. The other noticeable feature is that the rate at which data are being archived has increased by roughly a factor of 4.5 during 1995. Most of this increase comes from increased data flow from the FDSN and from several array components of IRIS.
In addition to the fully managed data now totaling more than two terabytes, the DMC also has data from a variety of other sources (primarily from PASSCAL experiments) that are maintained and distributed as assembled data sets. As of January 1996, the PASSCAL program had contributed a total of thirty-four assembled data sets with a total volume of 91 gigabytes.
Meeting the Data Needs of the Seismological Research Community
Although a fundamental goal of the IRIS DMC in Seattle is to ensure the long-term viability of the data archive, the IRIS DMC has become one of the major sources of seismological data for the United States as well as the international seismological research community. For the past several years the IRIS DMC has distributed a greater volume of data to the seismological community than the IRIS GSN has generated. Perhaps this fact, more than any other, provides testimony to the active use of the IRIS DMS.
In the initial planning stages of the IRIS DMS, it was projected that the IRIS DMC would service approximately 200 requests for GSN data per year. Figure 2 shows that the IRIS DMS has exceeded original expectations by more than two orders of magnitude; over 37,500 data shipments were made in 1995. Figure 2 also shows how the data shipments have continued to increase in a nearly exponential manner. The diagram includes all customized data and all assembled data products shipped.
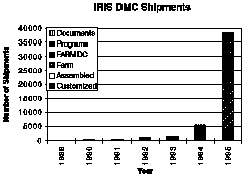
Figure 2. The most dramatic measure of the success of the IRIS DMC is the number of requests for data, programs, and documentation that are serviced per year. This diagram reflects that growth. Customized requests are specific requests for selected portions of the archive, Assembled are items distributed as complete data sets, the FARM is the online collection of SEED volumes containing data from the largest events, and FARM DC represents shipments of FARM volumes that went to data centers around the world and not to scientists.
There are a variety of different ways to measure the output of the IRIS DMS. Another clear estimate of its ever-increasing output is the number of individual seismograms shipped. In 1995, IRIS DMC shipped nearly 20 million seismograms from only our two most active data distribution mechanisms, namely customized data requests and FARM products. Although 1989 and 1990 were extremely busy years for the IRIS DMC (more than 100,000 seismograms were shipped in 1990), the more recent years completely dwarf the early years of the DMC.
User Access Tools
One of the principal goals of the IRIS DMS is to provide easy data access to the worldwide seismological community. For this reason the IRIS DMS has developed a variety of tools to simplify making requests for waveform and parametric data. Figure 3 identifies the major data access methods developed at the IRIS DMC to gain access to its data holdings. Any of these methods allows a user to make a customized request for specific samples of the archive.
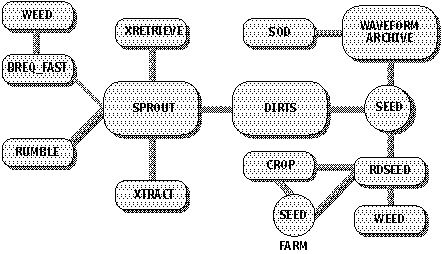
Figure 3. This diagram shows most of the user access tools that exist at the DMC. In general each tool has its particular strengths and is best suited for specific types of requests. Of particular importance are the two new access tools, WEED and CROP, since they represent the interfaces that should exhibit the greatest growth in usage for the future.
DIRTS. The heart of the IRIS DMC system is the DIRTS database management system. This is an IRIS-developed database management system (DBMS) built upon a commercially available DBMS, db_VISTA by Raima Corporation. It is a network database that provides extremely high-speed access to any information contained in various independent databases. Presently we store information in databases that are divided by specific networks and years. The only exception to the segmentation by network and year is for the IRIS DBMS itself, which includes the IRIS/IDA (II) subnetwork, the IRIS/USGS (IU) subnetwork, the GDSN (AS, SR, DW, HG RS) network of the USGS, and for historical reasons the TERRAscope network (TS). The databases themselves contain information about specific stations, the channels they record, the channel's response to ground motion in minute detail, and comments. Additionally, each database contains information about seismic events and their locations, times, and magnitudes, and other event information. The IRIS DMC presently manages a total of 85 databases for the various networks and years for which it has seismological data. The seismograms themselves are stored in robotic systems capable of storing a total of ten terabytes (1013 bytes) of data. When users make requests via any of the access tools depicted in Figure 3, programs at the DMC extract information from the various databases, recover waveforms from the mass storage systems, and combine them to produce SEED volumes containing the requested information.
Although not specifically shown in Figure 3, the IRIS DMC Electronic Bulletin Board remains a frequently used method to contact the IRIS DMC and to invoke several of these access tools. A large amount of information about stations, events, hypocenter searching, online manuals, and access to the methods of making customized requests for data can be found in the main menu of the bulletin board.
Specific manuals for access tools can be recovered electronically in one of three ways:
- Sending e-mail to info@dmc.iris.washington.edu with the subject line "manuals" and the body with the tool name (breq_fast, rumble, etc.).
- Accessing the manuals through anonymous ftp on machine dmc.iris.washington.edu in directory ~ftp/pub/manuals.
- Using the WWW Uniform Resource Locator for the IRIS DMC, http://www.iris.washington.edu.
BREQ_FAST. The most frequently used access tool is BREQ_FAST. It is an e-mail-based tool that allows users to specify stations, channels, and time windows in a file with a specific format. When completed the BREQ_FAST request file can be sent to the DMC by e-mail.
RUMBLE. Similar in use to BREQ_FAST is RUMBLE (Requests Users Make By Listing Events). This tool is also e-mail-based. The user constructs a file of another format that identifies events of interest. For instance, users can make requests for data from earthquakes from a given geographic area or for various magnitude sizes, depths, or times. Users can indicate data preferences for specific stations and channels or limit the data recovered to specific event-station distances or azimuths. It is an extremely powerful tool that users can master quickly.
RETRIEVE. For users who have high-speed Internet access to the IRIS DMC (mostly users in North America, and, at certain times of the day, other users) two X-Windows-based tools are available. XRETRIEVE is similar in function to BREQ_FAST, except that users interact with a graphical user interface (GUI). Data requests for specific networks, stations, channels, and time periods can be made by pointing and clicking.
XTRACT. This is a very powerful X-Windows-based tool that gives users full access to all of the information in the DIRTS DBMS. It produces very complex X-Windows displays and as such requires very good Internet connectivity. RUMBLE-type requests can be made using XTRACT, or specific pieces of information from the DBMS can be extracted and printed or saved to a file. XTRACT is currently being changed to a client-server architecture.
SPROUT. The IRIS DIRTS DBMS is a network database. Nevertheless, it provides a structured query language (SQL) interface that is normally reserved for relational database management systems. Users who are familiar with or are interested in learning structured query language can connect directly to the SPROUT system from within the IRIS DMC Electronic Bulletin Board.
SOD. Standing Order for Data (SOD) is a relatively new method of making routine data requests. SOD allows a user, normally a station operator or a seismologist with a specific need for data from specific stations, to make requests for data that the DMC has not yet received. The SOD request is similar in function to the BREQ_FAST request file format with a few additions. As data that match a SOD request arrive at the DMC, copies of the waveforms are stored in mini-SEED volumes. Periodically, as specified by the user, these mini-SEED volumes are transferred electronically or by tape to the requester.
WEED. Another new and powerful tool is WEED, Windows Extracted from Event Data, that in some ways is a seismological travel-time calculator. WEED is driven by three files with specific formats. The STATION file contains information about seismic stations--their locations, the types of channels they record, etc. The WEED EVENT file contains information about seismic events, their locations, origin times, magnitudes, and Flynn-Engdahl regions. The final WEED file is called the DATA WINDOW DEFINITION file. This file contains information about the time windows a user wishes to use for data extraction relative to modeled travel times. For instance, a user can specify time windows starting 60 seconds before the P phase and continuing for five minutes after the PKIKP phase. It is worthwhile to note that the STATION and EVENT files do not have to refer to stations and events managed at the IRIS DMC but could apply to a regional network, a PASSCAL experiment, or any other independent collection of instruments. The IRIS DMC maintains WEED station and event files in its anonymous ftp area for users wishing to make requests for data at the IRIS DMC or other data centers able to process the BREQ_FAST format. WEED is a program that runs on a seismologist's local workstation. GUI-based tools allow one to select specific stations and events based upon a large number of parameters, including station-event relationships. From the input STATION, EVENT, and DATA WINDOW DEFINITION files, WEED builds what is called a SUMMARY_FILE that contains information about the various stations, events, and time windows of interest. WEED allows the user to hand-edit these files. By clicking on another button, a BREQ_FAST request is built and sent to the IRIS DMC or other data center. It is a new but extremely powerful tool.
FARM. The growth in the number of data requests serviced in the early years was truly remarkable. To a large degree it provided the incentive to develop the Fast Archive Recovery Method (FARM) of data access. Understanding the pattern of data requests for many years allowed the IRIS DMS to identify what data were of most interest to seismological researchers. Based on this understanding, the IRIS DMC routinely constructs data volumes in SEED format for all earthquakes larger than magnitude Mw = 5.7 (Mw = 5.5 for events deeper than 100 km) and places them online in an anonymous ftp area. These volumes can then be accessed, without having to interact with the IRIS DMC staff, at anonymous ftp machine dmc.iris.washington.edu in directory pub/farm and then in specific subdirectories broken down by year and event time. Users can also directly access the FARM products using the World Wide Web and URL http://www.iris.washington.edu/cgi-bin/wilberII_page1.pl.
Data windows are generally at least one hour for even the broadband channels, and so there is a high probability that the desired data are in the FARM. Data shipment patterns indicate that this is the case. FARM products are stored in a RAID disk system at the DMC and therefore should have very high availability. Roughly 45 gigabytes of RAID disk space are dedicated to the FARM. Nevertheless, some less frequently accessed FARM products must be migrated off the RAID system and must exist in DMC mass storage systems. Access tools still allow researchers to gain access to these offline FARM products without the involvement of IRIS DMC staff.
CROP. The only disadvantage of the FARM is that some volumes are extremely large. For instance, the 1994 Bolivian earthquake FARM product is more than 100 megabytes in size. It is therefore too large to transfer electronically to most institutions. For this reason the Customized Reduction Of Products (CROP) access tool was created. This tool allows individuals to extract subsets of the data in a given FARM volume, produce a smaller volume in SEED format, and then electronically transfer that volume.
What's Next?
With the foundation of the IRIS DMS well established, the DMS is turning its attention to a variety of new issues. During 1996 and 1997 IRIS should see progress in the following areas:
- Providing access to a wider variety of seismological data, including perhaps GPS and strong-motion data
- Progress in providing access to data from more regional networks
- Improving data flow from PASSCAL experiments
- Demonstrating the use of Inmarsat satellites to access very remote GSN stations for the SPYDER system
- Investigating routine application of a variety of procedures to data at the DMC
- Expanding the IRIS outreach to the K-12 community
- Developing software that can be used at distributed data centers for quality control and generation of SEED volumes
- Promoting networked data centers
- Developing software needed to handle the increasing volume of data
How to Reach the IRIS DMC
The IRIS Data Management System exists to support seismology within the United States and around the world. We encourage all seismologists to take advantage of the facilities we offer. We can be reached at
IRIS DMC
1408 NE 45th Street, Suite 205
Seattle, Washington 98105
USA
Our principal data access tools are the electronic bulletin board
telnet dmc.iris.washington.edu
userid: bulletin
password: board
To access the data access tools select the "r" option to request data from the main menu of the bulletin board. The tools available there include xretrieve, xtract, sprout, and CROP. SPYDERTM is available directly from the main menu of the bulletin board.
Our World Wide Web Uniform Resource Locator (URL) is http://www.iris.washington.edu.
SRL encourages guest columnists to contribute to the "Electronic Seismologist." Please contact Steve Malone with your ideas. His e-mail address is steve@geophys.washington.edu.
Posted: 10 February 1999
URL's updated: 21 January 2003